Hi all,
It’s not new for Oracle DBAs the countless great tools we have out of the box to help us out with our daily tasks, such as ORAchk/EXAchk/ODAchk, Database Security Assessment Tool (DBSAT), Hang Manager, Cluster Health Advisor (CHA), Cluster Verification Utility (CVU), Memory Guard, Tracefile Analyzer (TFA) with tools like oratop, procwatcher, oswatcher, pstack, RDA, and the list goes on and on…
The good news is, most of the tools are now together on the Autonomous Health Framework (AHF), since version 12.2. None of those tools are running by default though, so you might need to choose some to start and enable on your environment.
But out of all this list, what if we could choose the top 5 features we can and should use as a start for Exadata Environment? Well, I did mine, see it below.
Oh, and by the way, you don’t pay anything else for them, counting you already have Oracle Support Services!
1. Cluster Health Advisor – Calibrate your Exa Environment!
Available along with the AFH since 12.2, the CHA works along the Cluster Health Monitor to provide you fine-grained notifications and correlations about your environment. And when I say it, I mean it: YOUR environment. This is because the CHA works better if you calibrate it with your statistics. As usual, not the worse problematic day or the low workload night, but an average day which can be used as a reference. All this is stored in the GIMR (as shown below) and used for future comparison and model inference.
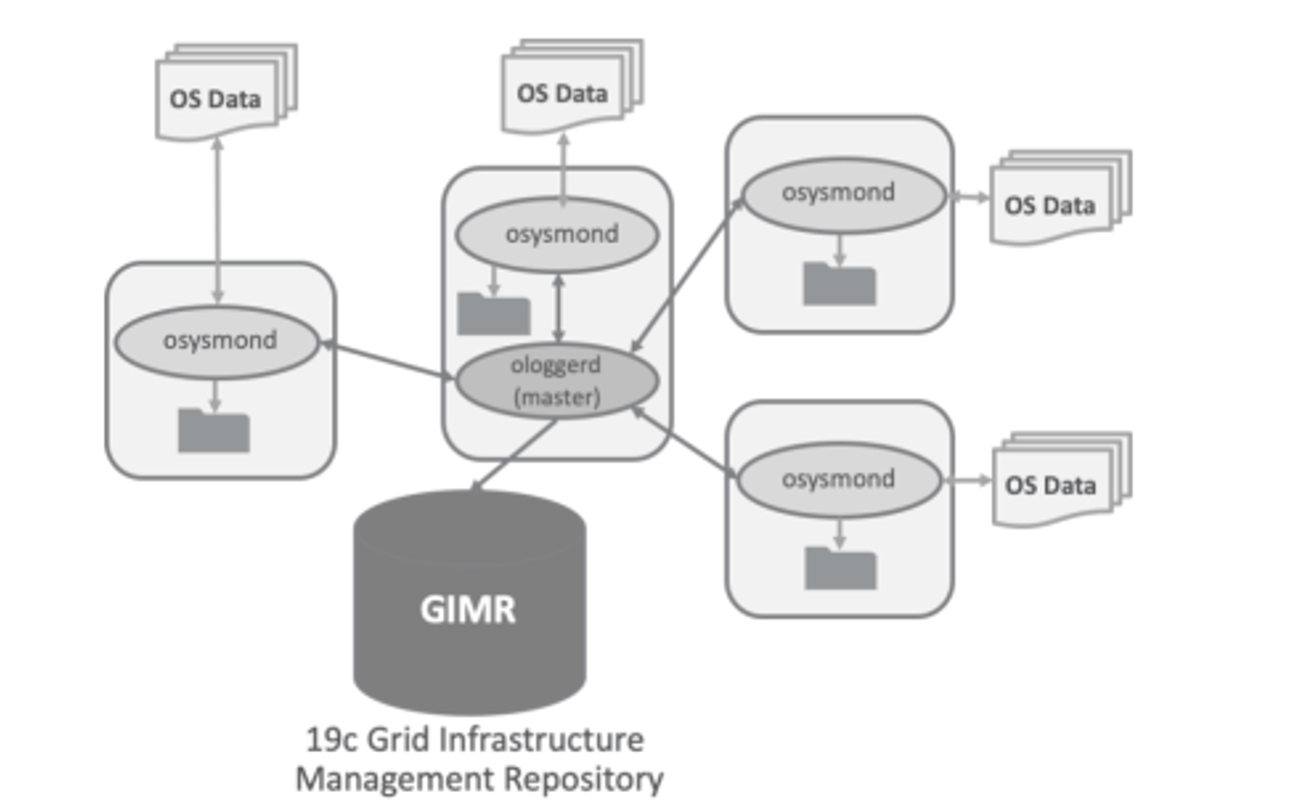

This means the CHA is not a long list of IFs with fixed metrics, but an intelligent tool monitoring over 127 processes that perform work based on your workload. Not only this, the CHA is enriched with Machine Learning algorithms that model over 30 known DB problems based on over 150 metric predictors.
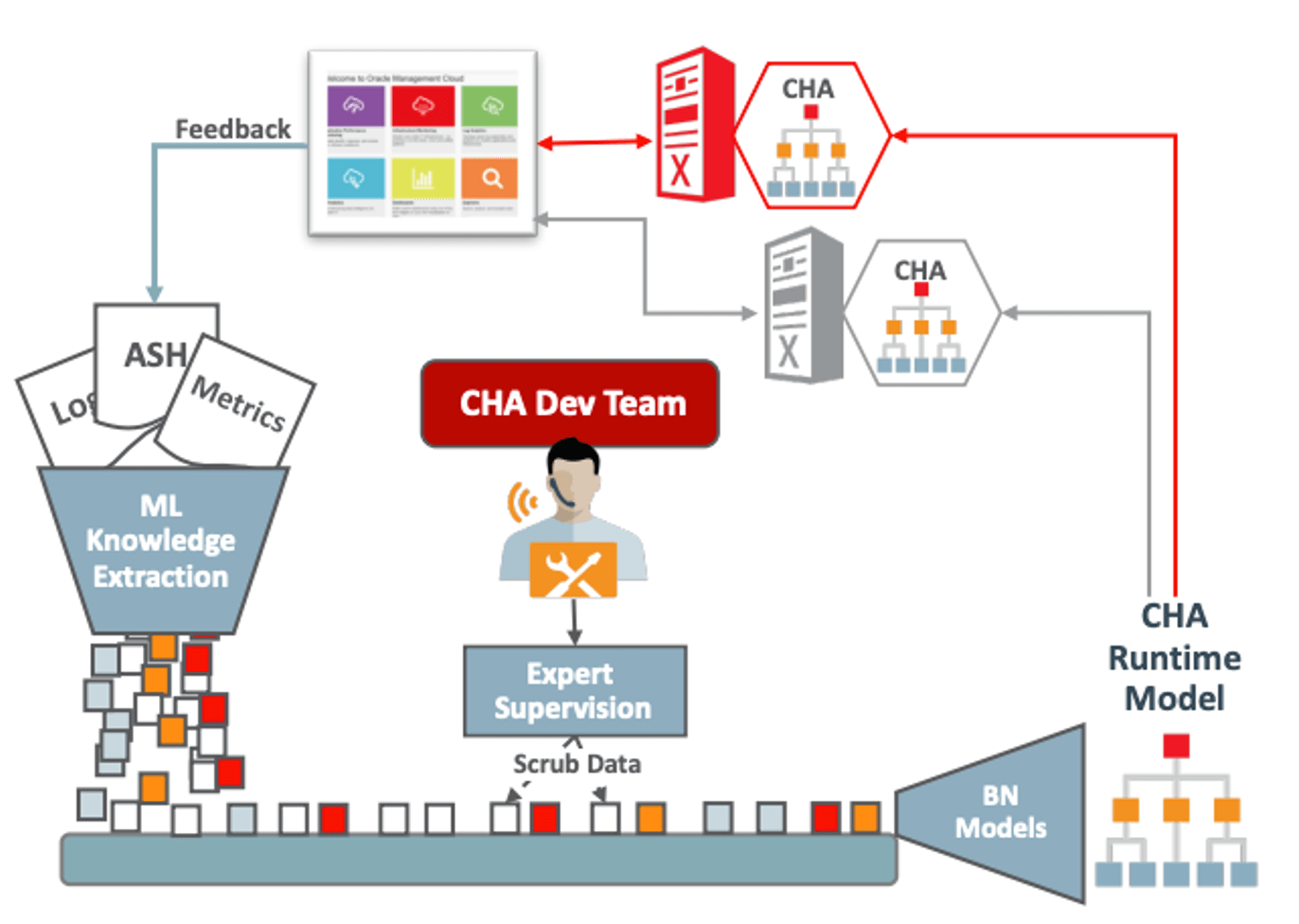
An example of inference can be seen below, where network and Global Cache statistics are used to inference a network issue.
Not rocket science, but always nice to have someone digesting tons of logs and metrics and reaching this sort of conclusion unassisted, right? You as DBA can steal all credits for the finding, no hard feelings.
And this is just one of the things CHA provides. It has tons of other functionalities. You should try using it more!
2. EXAchk – Daily Automated Runs (and Reports)
Most likely if you have an Exadata, you are used to running from time to time an EXAchk to review the recommendations and best practices for your environment. It’s something that requires almost no effort to run and to copy the reports, or you most likely have created an script to do so. What if I tell you Oracle has now automated this with AHF?
All you need to do is to confirm the scheduled runs and set the address for the reports to be sent. Find below a quick Cheatsheet:
a. Checking Status of the EXAchk
[root@exa01dbadm01 ~]# exachk -d info ------------------------------------------------------------ Master node = exa01dbadm01 exachk daemon version = 211300 Install location = /opt/oracle.ahf/exachk Started at = Wed Jun 16 11:58:03 MDT 2021 Scheduler type = TFA Scheduler [root@exa01dbadm01 ~]# exachk -d status exachk is using TFA Scheduler. TFA PID: 369350
b. Checking Status of TFA Daemon Status and Auto Start
[root@exa01dbadm01 ~]# ahfctl statusahf .-----------------------------------------------------------------------------------------------------. | Host | Status of TFA | PID | Port | Version | Build ID | Inventory Status | +--------------+---------------+--------+------+------------+----------------------+------------------+ | exa01dbadm01 | RUNNING | 369350 | 5000 | 21.1.3.0.0 | 21130020210607124914 | COMPLETE | | exa01dbadm02 | RUNNING | 118950 | 5000 | 21.1.3.0.0 | 21130020210607124914 | COMPLETE | '--------------+---------------+--------+------+------------+----------------------+------------------' ------------------------------------------------------------ Master node = exa01dbadm01 exachk daemon version = 211300 Install location = /opt/oracle.ahf/exachk Started at = Wed Jun 16 11:58:03 MDT 2021 Scheduler type = TFA Scheduler ------------------------------------------------------------ ID: exachk.autostart_client_exatier1 ------------------------------------------------------------ AUTORUN_FLAGS = -usediscovery -profile exatier1 -syslog -dball -showpass -tag autostart_client_exatier1 -readenvconfig COLLECTION_RETENTION = 7 AUTORUN_SCHEDULE = 3 2 * * 1,2,3,4,5,6 ------------------------------------------------------------ ------------------------------------------------------------ ID: exachk.autostart_client ------------------------------------------------------------ AUTORUN_FLAGS = -usediscovery -syslog -tag autostart_client -readenvconfig COLLECTION_RETENTION = 14 AUTORUN_SCHEDULE = 3 3 * * 0 ------------------------------------------------------------ Next auto run starts on Jun 17, 2021 02:03:00 ID:exachk.AUTOSTART_CLIENT_EXATIER1
c. Gather EXAchk Next Automated Run
[root@exa01dbadm01 ~]# exachk -d nextautorun Next auto run starts on Jun 17, 2021 02:03:00 ID:exachk.AUTOSTART_CLIENT_EXATIER1 [root@exa01dbadm01 ~]#
d. Changing EXAchk Notifications:
[root@exa01dbadm01 ~]# exachk -get NOTIFICATION_EMAIL,AUTORUN_SCHEDULE,COLLECTION_RETENTION ------------------------------------------------------------ ID: exachk.autostart_client_exatier1 ------------------------------------------------------------ COLLECTION_RETENTION = 7 AUTORUN_SCHEDULE = 3 2 * * 1,2,3,4,5,6 ------------------------------------------------------------ ------------------------------------------------------------ ID: exachk.autostart_client ------------------------------------------------------------ COLLECTION_RETENTION = 14 AUTORUN_SCHEDULE = 3 3 * * 0 ------------------------------------------------------------ [root@exa01dbadm01 ~]# exachk -id autostart_client -set NOTIFICATION_EMAIL=boesing@pythian.com Updated attribute ['NOTIFICATION_EMAIL=boesing@pythian.com'] for Id[exachk.AUTOSTART_CLIENT] Successfully copied Daemon Store to Remote Nodes [root@exa01dbadm01 ~]# exachk -get NOTIFICATION_EMAIL,AUTORUN_SCHEDULE,COLLECTION_RETENTION ------------------------------------------------------------ ID: exachk.autostart_client_exatier1 ------------------------------------------------------------ COLLECTION_RETENTION = 7 AUTORUN_SCHEDULE = 3 2 * * 1,2,3,4,5,6 ------------------------------------------------------------ ------------------------------------------------------------ ID: exachk.autostart_client ------------------------------------------------------------ NOTIFICATION_EMAIL = boesing@pythian.com COLLECTION_RETENTION = 14 AUTORUN_SCHEDULE = 3 3 * * 0 ------------------------------------------------------------ [root@exa01dbadm01 ~]# exachk -id autostart_client_exatier1 -set NOTIFICATION_EMAIL=boesing@pythian.com Updated attribute ['NOTIFICATION_EMAIL=boesing@pythian.com'] for Id[exachk.AUTOSTART_CLIENT_EXATIER1] Successfully copied Daemon Store to Remote Nodes [root@exa01dbadm01 ~]# exachk -get NOTIFICATION_EMAIL,AUTORUN_SCHEDULE,COLLECTION_RETENTION ------------------------------------------------------------ ID: exachk.autostart_client_exatier1 ------------------------------------------------------------ NOTIFICATION_EMAIL = boesing@pythian.com COLLECTION_RETENTION = 7 AUTORUN_SCHEDULE = 3 2 * * 1,2,3,4,5,6 ------------------------------------------------------------ ------------------------------------------------------------ ID: exachk.autostart_client ------------------------------------------------------------ NOTIFICATION_EMAIL = boesing@pythian.com COLLECTION_RETENTION = 14 AUTORUN_SCHEDULE = 3 3 * * 0 ------------------------------------------------------------
e. Change EXAchk Schedule and Retention
[root@exa01dbadm01 ~]# exachk -id autostart_client_exaier1 –set "AUTORUN_SCHEDULE=0 3 * * *" -> Time= 3 AM daily [root@exa01dbadm01 ~]# exachk-id autostart_client –set "collection_retention=90"
f. EXAchk: Testing Email Sending and Running EXAchk Report over email
This is for ad-hoc testing to check about email sending, out of the scheduled runs.
[root@exa01dbadm01 ~]# exachk -testemail notification_email=boesing@pythian.com
Email Successfully sent to ['boesing@pythian.com'] from 'root@exa01dbadm01
[root@exa01dbadm01 ~]# exachk -sendemail notification_email=boesing@pythian.com
Searching for running databases . . . . .
. . . . . . . . . . . .
List of running databases registered in OCR
1. xxxxxx
2. yyyy
3. None of above
Select databases from list for checking best practices. For multiple databases, select 3 for All or comma separated number like 1,2 etc [1-3][3].
[...]
Detailed report (html) - /u01/app/oracle/oracle.ahf/data/exa01dbadm01/exachk/user_root/output/exachk_exa01dbadm01_xxxxx_061621_134748/exachk_exa01dbadm01_xxxxx_061621_134748.html
UPLOAD [if required] - /u01/app/oracle/oracle.ahf/data/exa01dbadm01/exachk/user_root/output/exachk_exa01dbadm01_xxxxxx_061621_134748.zip
Email Successfully sent to ('boesing@pythian.com',) from 'root@exa01dbadm01' with attachment
3. TFA – Sanitize and Mask Options
Even with all the concerns on sensitive data being more and more relevant, this is something that actually surprised me. It’s possible to Sanitize and Mask data in collections. For example, mask will hide your inner data (let’s say table names):
[root@exa01dbadm01 ~]# tfactl diagcollect -srdc ORA-00600 -mask
Sanitize will hide your hardware setting. Not that useful if you have an Exadata, but might be interesting if you have commodity hardware you don’t want Oracle to know about.
[root@exa01dbadm01 ~]# tfactl diagcollect -srdc ORA-00600 -sanitize
4. TFA Changes – “Nothing was Changed” Resolver Tool
This is for all the DBAs which had already this dialogue:
Client: Yesterday was running fine, and today it’s veeeery slow. Nothing was changed!
DBA: Something changed, that’s for sure.
Client: Absolutely nothing changed.
So now we can access if indeed nothing changed from the client’s perspective (perhaps an automatic statistics gathering or something) or if anybody did something and is hard to identify.
It takes parameters from OS and DB and tracks of old and new values, reporting changes:
[root@exa01dbadm01 ~]# tfactl changes Output from host : exa01dbadm02 ------------------------------ No Changes Found Output from host : exa01dbadm01 ------------------------------ [Nov/14/2021 00:08:33.000]: [db.dbprod19.dbprod191]: Parameter: log_archive_dest_2: Value: service=dbprod19stb => ASYNC NOAFFIRM delay=240 optional compression=disable max_failure=0 reopen=300 db_unique_name=dbprod19stb net_timeout=300 [Nov/14/2021 00:08:33.000]: [db.dbprod19.dbprod191]: Parameter: log_archive_dest_2: Value: service=dbprod19stb => valid_for=(online_logfile,all_roles)
5. Oracle Health Check Collections Manager
Not a surprise if you don’t know this tool, but I’d really recommend you do look for it now. It’s a great tool and as with everything in this post, it’s free!
Oracle Health Check Collections Manager is an APEX companion application to Oracle EXAchk that gives you an enterprise-wide view of your health check collection data. All you need to have is an APEX 4.2 or 5 version and deploy the tool. The main idea is that you can consolidate all your reports in one place and, as a plus, you can manage all your EXAchk reports across the time, including a view on the items regression you may have.
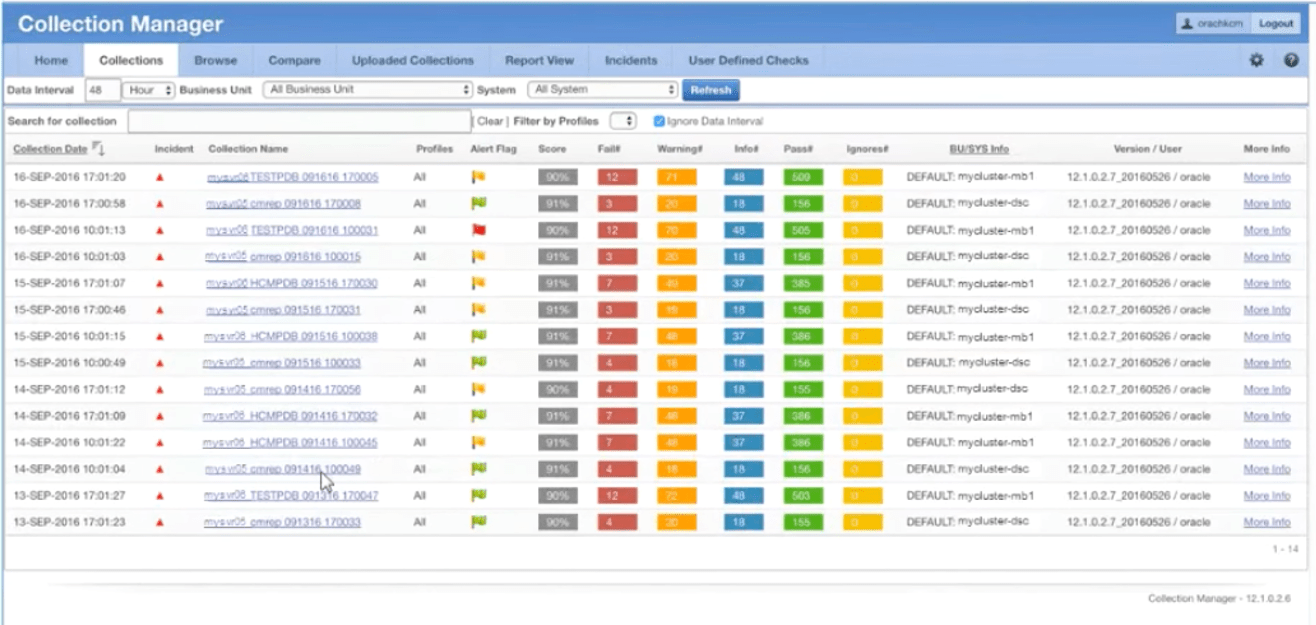
This is an example of the view of the collections:
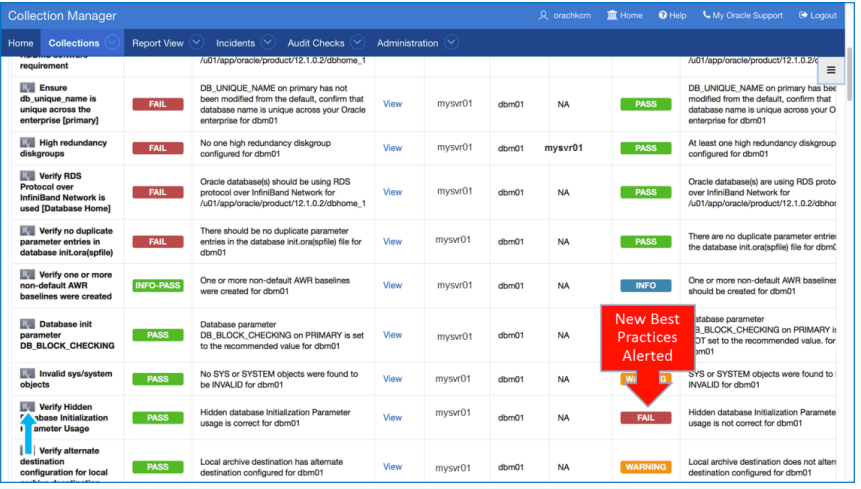
And this is an example of a new best practices failure:
Do you agree with my top list? Let me know your thoughts!






